 j
j
 j
j
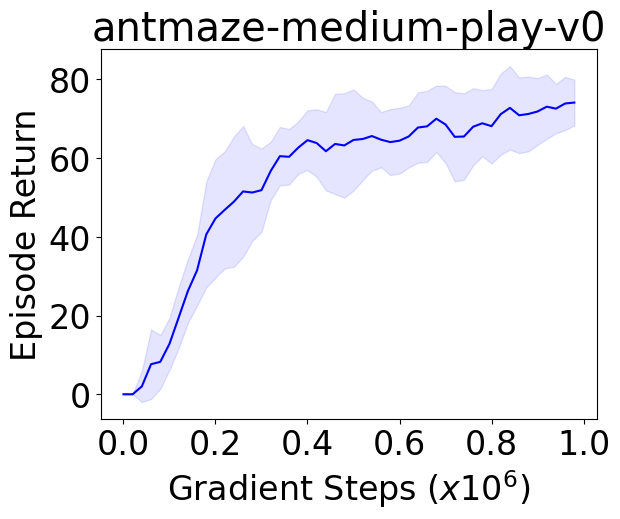
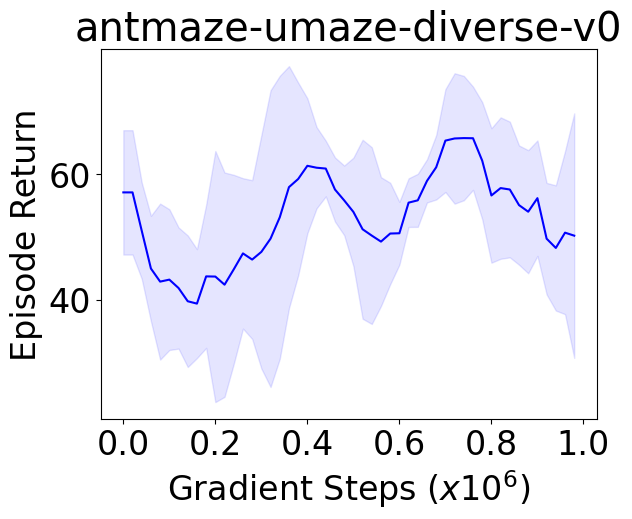
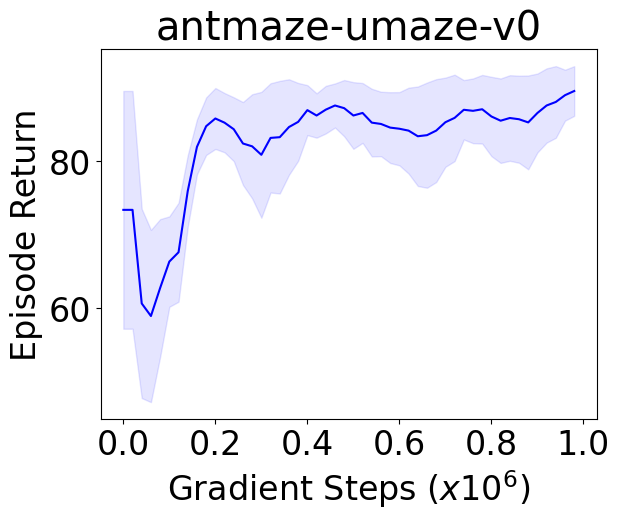
Behavior constrained policy optimization has been demonstrated to be a successful paradigm for tackling Offline Reinforcement Learning. By exploiting historical transitions, a policy is trained to maximize a learned value function while constrained by the behavior policy to avoid a significant distributional shift.
In this project, we propose closed-form policy improvement operators. We make the novel observation that the behavior constraint naturally motivates the use of first-order Taylor approximation, leading to a linear approximation of the policy objective.
Additionally, as practical datasets are usually collected by heterogeneous policies, we model the behavior policies as a Gaussian Mixture and overcome the induced optimization difficulties by leveraging the LogSumExp's lower bound and Jensen's Inequality, giving rise to a closed-form policy improvement operator.
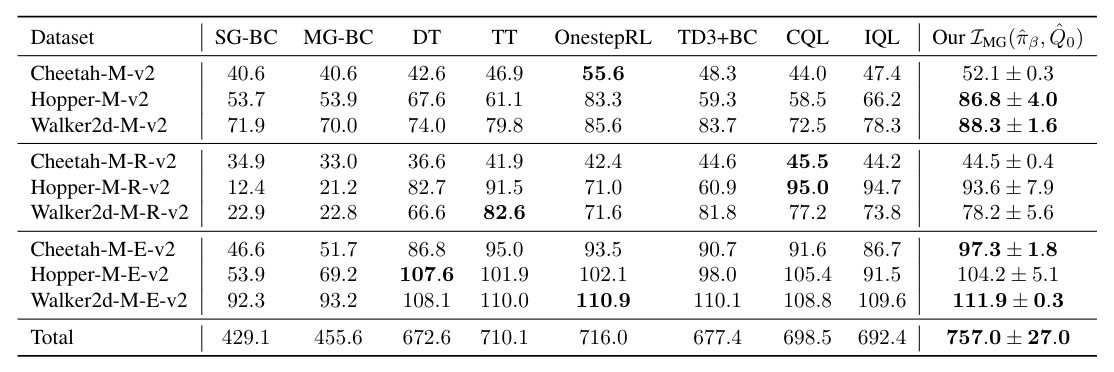
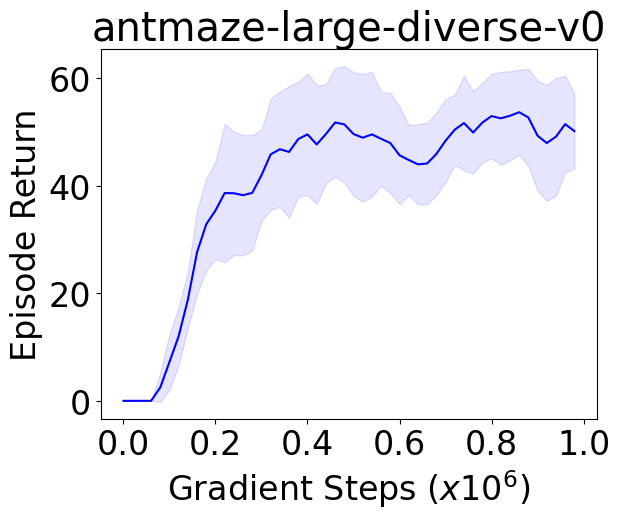
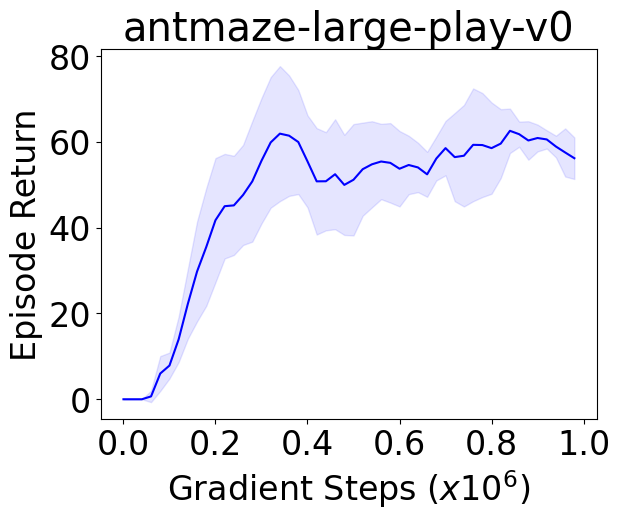
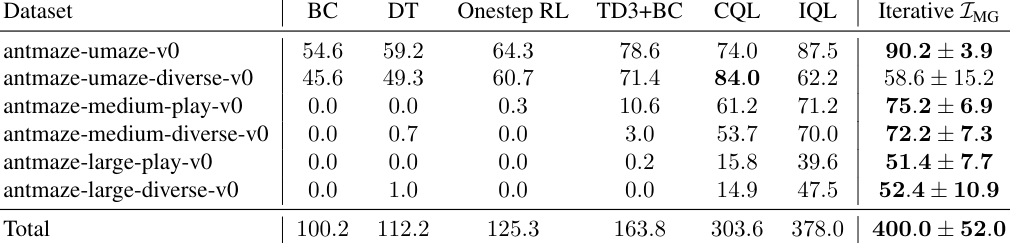
We instantiate both one-step and iterative offline RL algorithms with our novel policy improvement operators and empirically demonstrate {their} effectiveness over state-of-the-art algorithms on the standard D4RL benchmark.
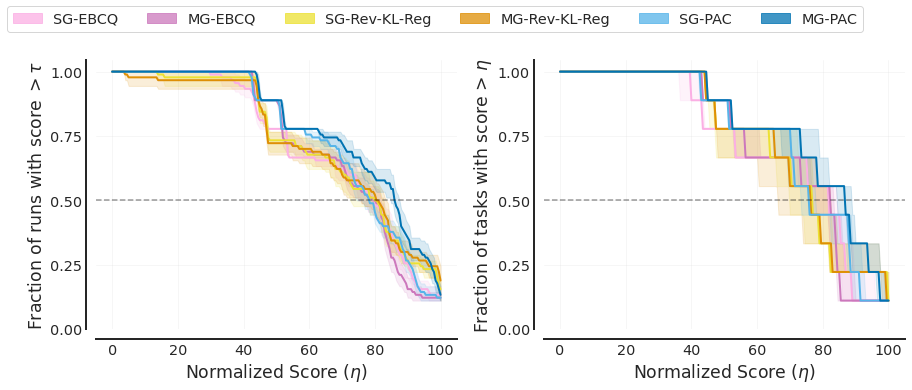

Here, I-MG (MG-PAC) and I-SG (SG-PAC) refer to our method.
Performance profiles (score distributions) for all methods on the 9 tasks from the D4RL MuJoCo Gym domain. The average score is calculated by averaging all runs within one task. Each task contains 10 seeds, and each seed evaluates for 100 episodes. Shaded area denotes 95% confidence bands based on percentile bootstrap and stratified sampling. The η value where the curves intersect with the dashed horizontal line y = 0.5 corresponds to the median, while the area under the performance curves corresponds to the mean.
To demonstrate the superiority of our methods over the baselines and provide reliable evaluation results, we follow the evaluation protocols proposed in (Agarwal et al., 2021). Specifically, we adopt the evaluation methods for all methods with N tasks × N seeds runs in total. Evaluation results demonstrate that our method outperforms the baseline methods by asignificant margin based on all four reliable metrics.
This project would not be possible without the following wonderful prior work.
Optimistic Actor Critic gave inspiration to our method, D4RL provides the dataset and benchmark for evaluating the performance of our agent, and RLkit offered a strong RL framework for building our code from.
@misc{li2022offline,
title={Offline Reinforcement Learning with Closed-Form Policy Improvement Operators},
author={Jiachen Li and Edwin Zhang and Ming Yin and Qinxun Bai and Yu-Xiang Wang and William Yang Wang},
journal={ICML},
year={2023},
}